Autoscaler
Scaling overview
Section titled “Scaling overview”ICC implements a dual-algorithm framework for intelligent autoscaling:
- Reactive Scaling Algorithm - Responds in real-time to performance signals (ELU > 90%, Heap > 80%)
- Trends Learning Algorithm - Analyzes historical patterns to predict future scaling needs
Reactive Scaling Algorithm
Section titled “Reactive Scaling Algorithm”When wattpro notices that one of the services is unhealthy, it sends a health alert to ICC. By default the reasons to send an alert are:
- high ELU (> 90%)
- high memory consumption (heap > 80%)
After receiving an alert ICC makes a decision to scale up or not based on alerts from other pods and historical data. When high load conditions end, the ICC will scale pods down automatically.
Trends Learning Algorithm
Section titled “Trends Learning Algorithm”The long-term scaling algorithm studies application scaling patterns and scales applications up and down in advance to anticipate demand fluctuations and optimize resource allocation.
On the Horizontal Pod Autoscaler page, you can see information about Kubernetes pod status and scaling events.
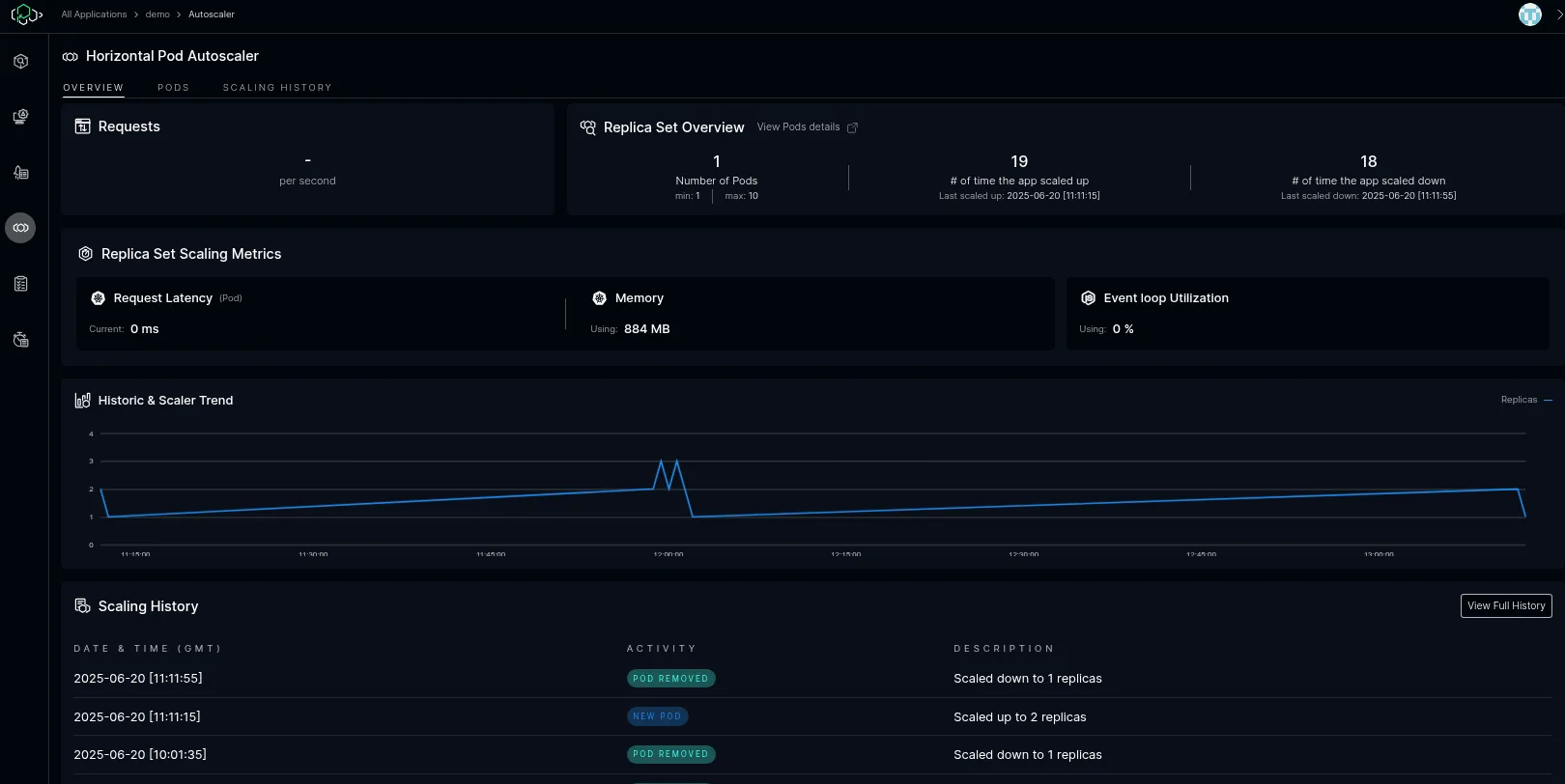
In the “Replica Set Scaling Metrics” section, you can see the aggregated metrics for all tracking subsystems for the current application.
The “Historic & Scaler Trend” chart shows the history of scaling decisions made by the ICC scaling algorithm.
In Pod Overview shows important information about individual pods including their state of health:
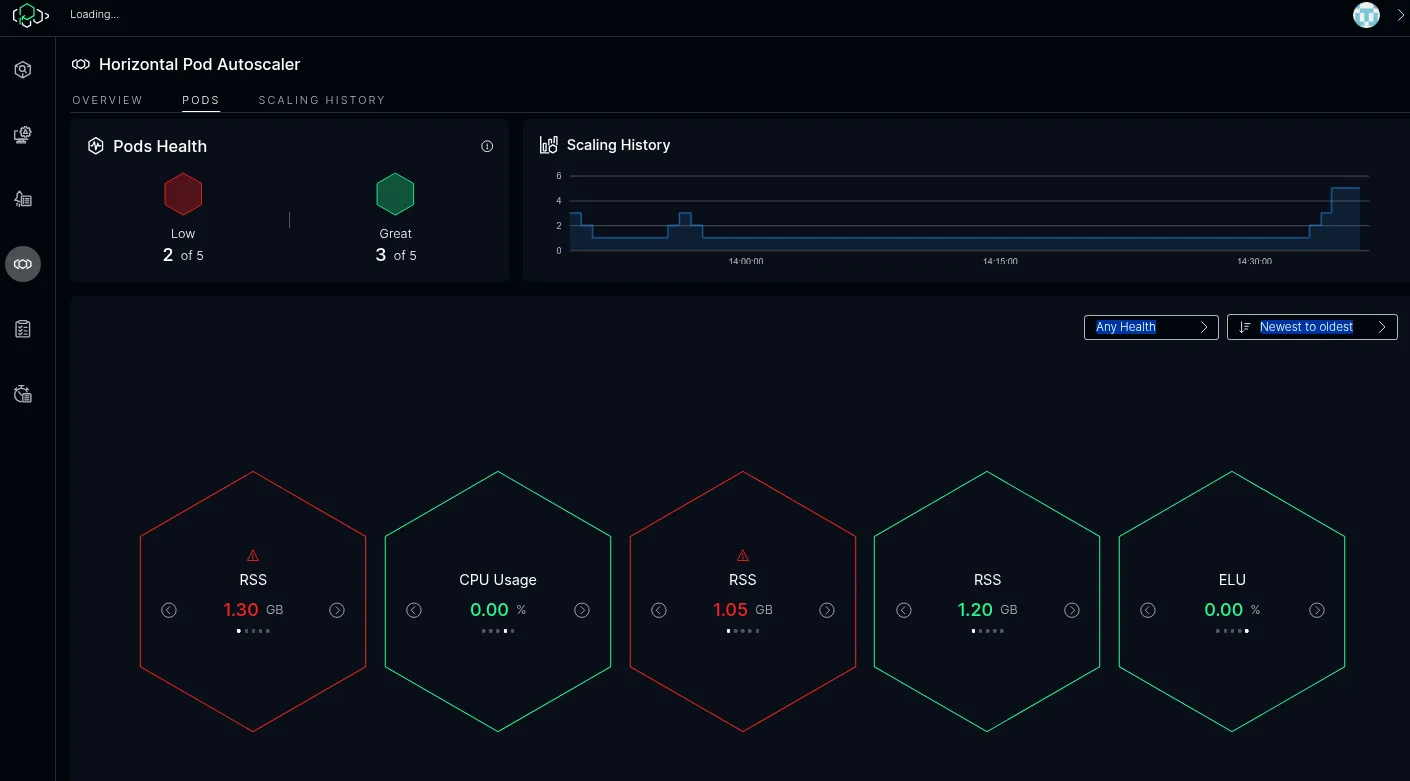
This shows how the system behaves in case of sudden heavy load, ramping up the number of pods:
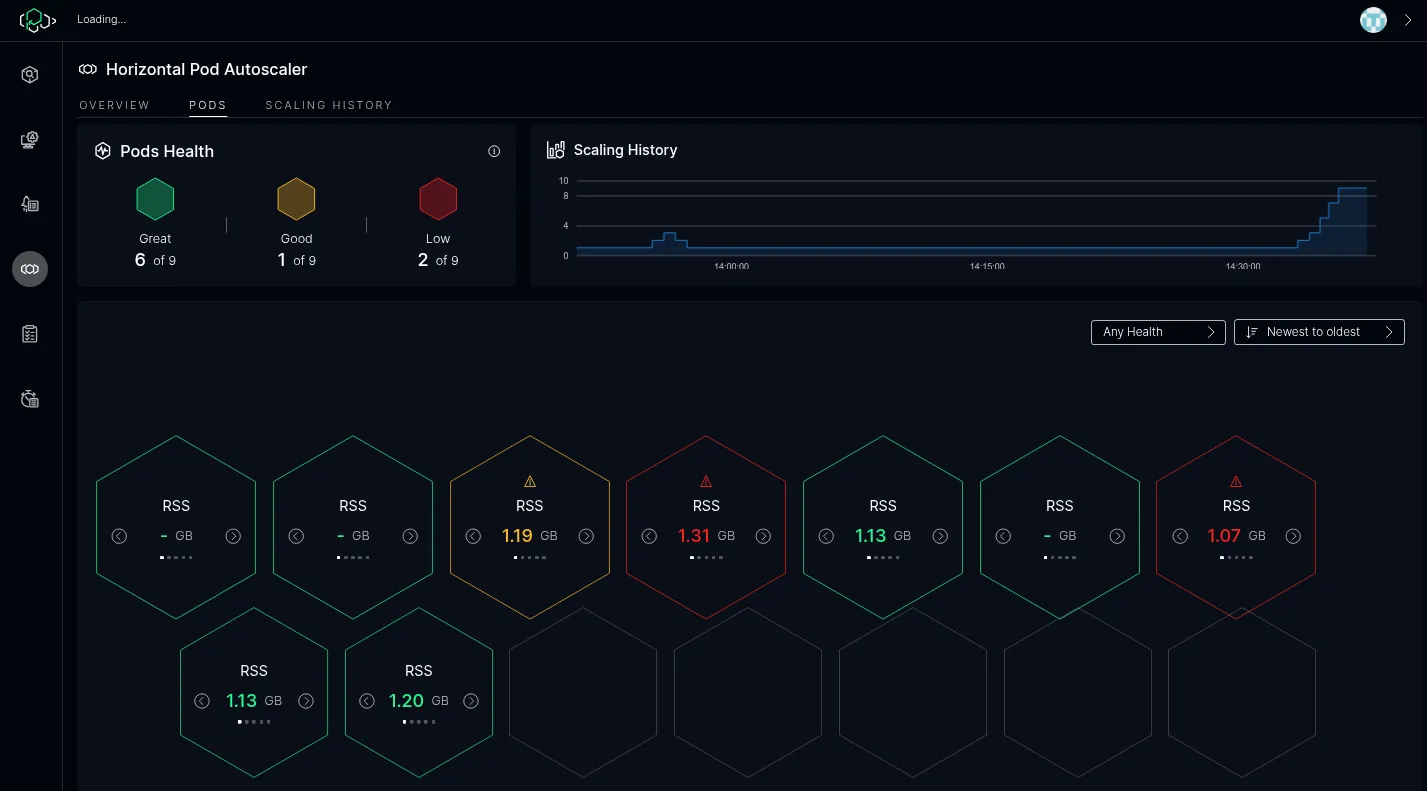
…after which the pods are all in good health.
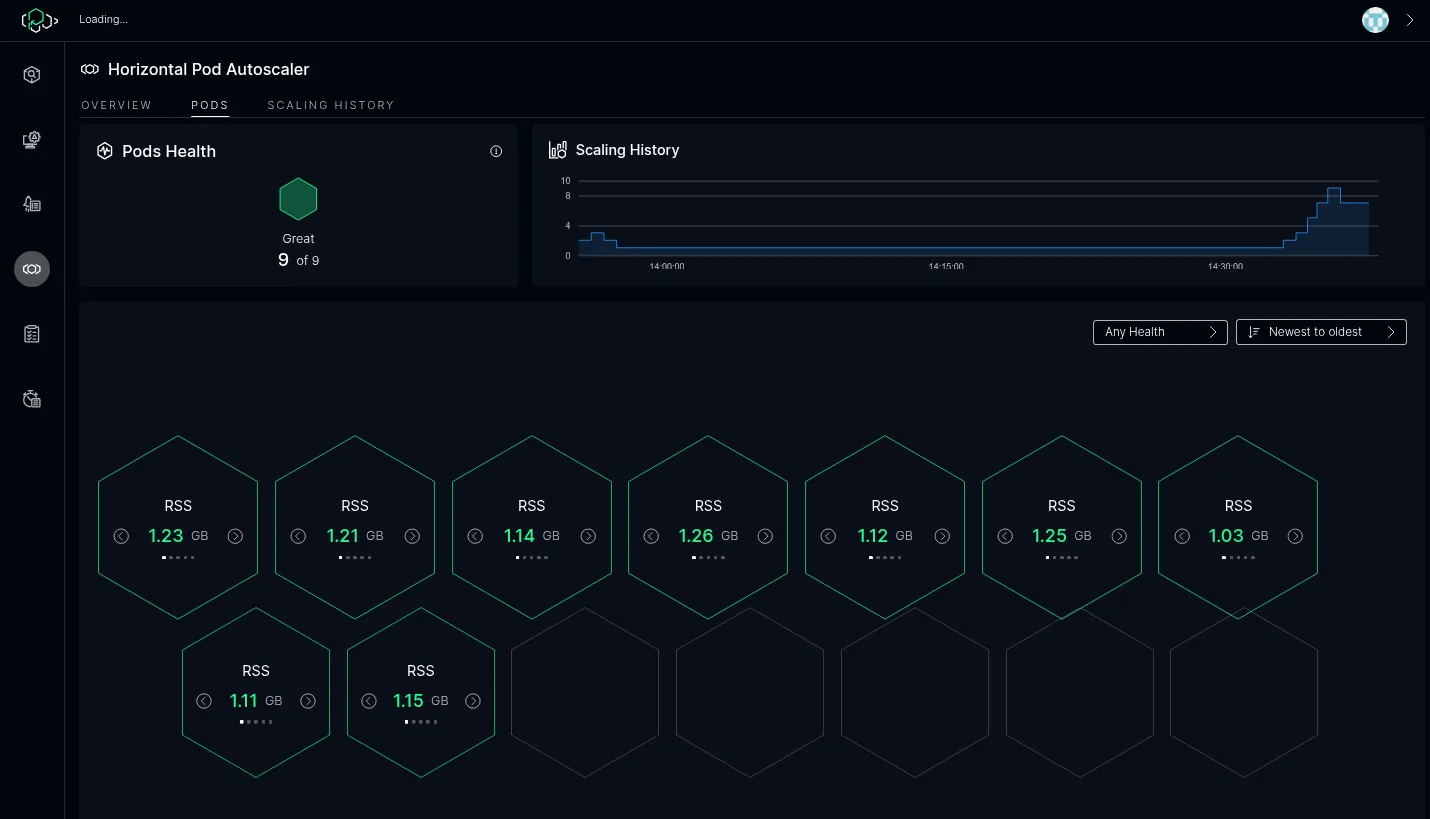
ICC then starts to scale down:
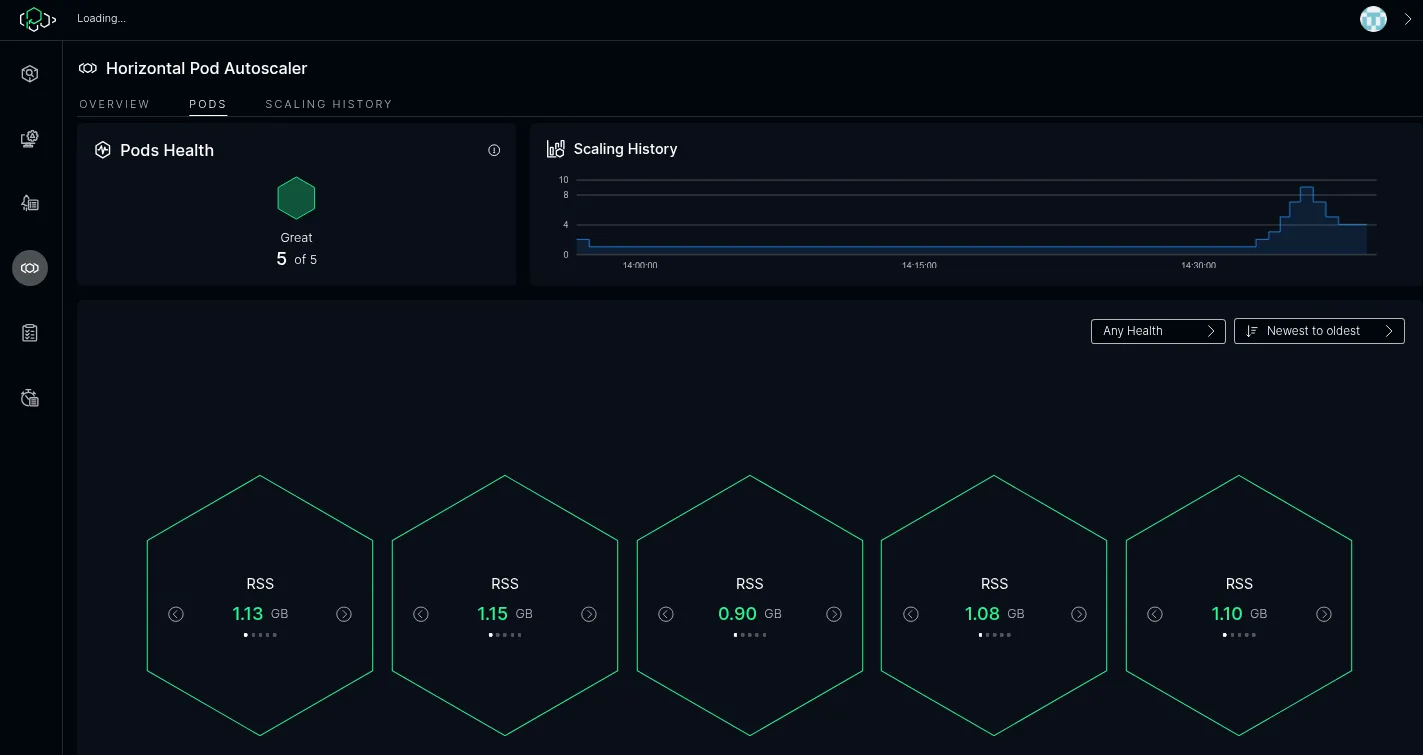
…eventually scaling down back to the minimum pod count if there is no traffic. The minimum and maximum amount of pods is configurable in ICC.
All the events are available in Scaling History:
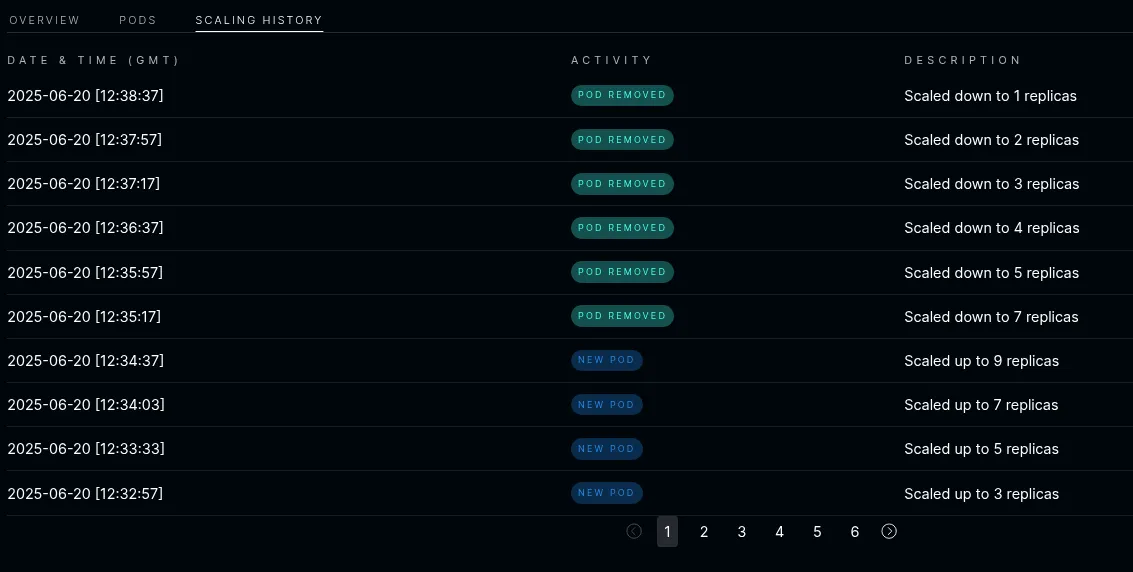
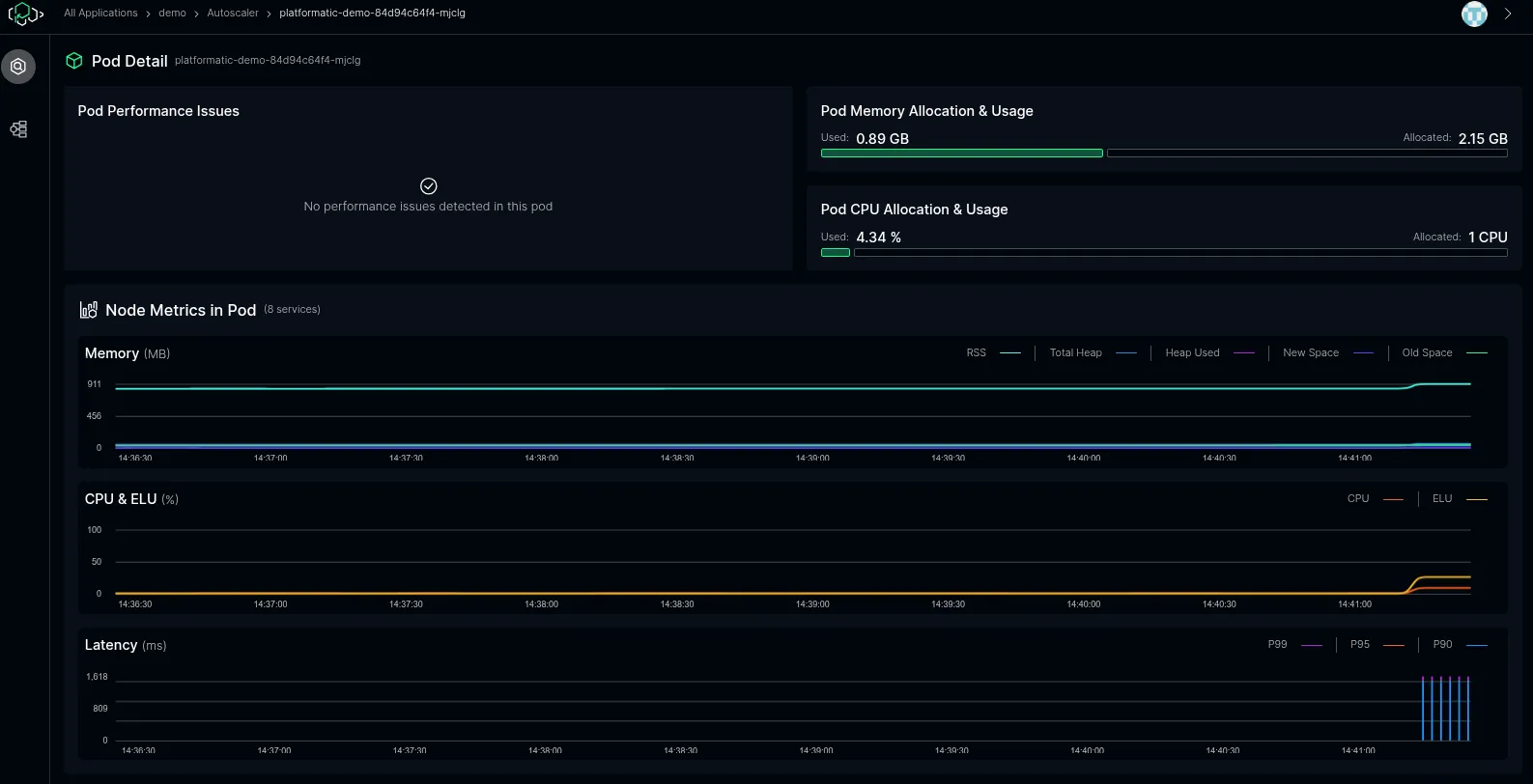
The Pod Detail screen shows detailed metrics for an individual pod: